转载于:https://blog.csdn.net/weixin_39408343/article/details/95984062
自己研究的东西会用到AST,就自己通过查阅资料,整理一下。
本文目录
第一部分:AST的作用
首先来一个比较形象的,转载自:AST-抽象语法树,讲述了为什么需要讲源代码转化为AST,总结就是:AST不依赖于具体的文法,不依赖于语言的细节,我们将源代码转化为AST后,可以对AST做很多的操作,包括一些你想不到的操作,这些操作实现了各种各样形形色色的功能,给你带进一个不一样的世界。
原文为:
抽象语法树简介
(一)简介
抽象语法树(abstract syntax code,AST)是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,这所以说是抽象的,是因为抽象语法树并不会表示出真实语法出现的每一个细节,比如说,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。抽象语法树并不依赖于源语言的语法,也就是说语法分析阶段所采用的上下文无文文法,因为在写文法时,经常会对文法进行等价的转换(消除左递归,回溯,二义性等),这样会给文法分析引入一些多余的成分,对后续阶段造成不利影响,甚至会使合个阶段变得混乱。因些,很多编译器经常要独立地构造语法分析树,为前端,后端建立一个清晰的接口。
抽象语法树在很多领域有广泛的应用,比如浏览器,智能编辑器,编译器。
(二)抽象语法树实例
(1)四则运算表达式
表达式: 1+3*(4-1)+2
抽象语法树为:

(2)xml
代码2.1:
- <letter>
- <address>
- <city>ShiChuang</city>
- </address>
- <people>
- <id>12478</id>
- <name>Nosic</name>
- </people>
- </letter>
抽象语法树

(3)程序1
代码2.2
- while b != 0
- {
- if a > b
- a = a-b
- else
- b = b-a
- }
- return a
抽象语法树

(4)程序2
代码2.3
- sum=0
- for i in range(0,100)
- sum=sum+i
- end
抽象语法树

(三)为什么需要抽象语法树
当在源程序语法分析工作时,是在相应程序设计语言的语法规则指导下进行的。语法规则描述了该语言的各种语法成分的组成结构,通常可以用所谓的前后文无关文法或与之等价的Backus-Naur范式(BNF)将一个程序设计语言的语法规则确切的描述出来。前后文无关文法有分为这么几类:LL(1),LR(0),LR(1), LR(k) ,LALR(1)等。每一种文法都有不同的要求,如LL(1)要求文法无二义性和不存在左递归。当把一个文法改为LL(1)文法时,需要引入一些隔外的文法符号与产生式。
例如,四则运算表达式的文法为:
文法1.1
- E->T|EAT
- T->F|TMF
- F->(E)|i
- A->+|-
- M->*|/
改为LL(1)后为:
文法1.2
- E->TE'
- E'->ATE'|e_symbol
- T->FT'
- T'->MFT'|e_symbol
- F->(E)|i
- A->+|-
- M->*|/
例如,当在开发语言时,可能在开始的时候,选择LL(1)文法来描述语言的语法规则,编译器前端生成LL(1)语法树,编译器后端对LL(1)语法树进行处理,生成字节码或者是汇编代码。但是随着工程的开发,在语言中加入了更多的特性,用LL(1)文法描述时,感觉限制很大,并且编写文法时很吃力,所以这个时候决定采用LR(1)文法来描述语言的语法规则,把编译器前端改生成LR(1)语法树,但在这个时候,你会发现很糟糕,因为以前编译器后端是对LL(1)语树进行处理,不得不同时也修改后端的代码。
抽象语法树的第一个特点为:不依赖于具体的文法。无论是LL(1)文法,还是LR(1),或者还是其它的方法,都要求在语法分析时候,构造出相同的语法树,这样可以给编译器后端提供了清晰,统一的接口。即使是前端采用了不同的文法,都只需要改变前端代码,而不用连累到后端。即减少了工作量,也提高的编译器的可维护性。
抽象语法树的第二个特点为:不依赖于语言的细节。在编译器家族中,大名鼎鼎的gcc算得上是一个老大哥了,它可以编译多种语言,例如c,c++,java,ADA,Object C, FORTRAN, PASCAL, COBOL等等。在前端gcc对不同的语言进行词法,语法分析和语义分析后,产生抽象语法树形成中间代码作为输出,供后端处理。要做到这一点,就必须在构造语法树时,不依赖于语言的细节,例如在不同的语言中,类似于if-condition-then这样的语句有不同的表示方法
在c中为:
- if(condition)
- {
- do_something();
- }
在fortran中为:
- If condition then
- do_somthing()
- end if
在构造if-condition-then语句的抽象语法树时,只需要用两个分支节点来表于,一个为condition,一个为if_body。如下图:

在源程序中出现的括号,或者是关键字,都会被丢掉。
第二部分:AST的流程
此部分让你了解到从源代码到词法分析生成tokens到语法分析生成AST的整个结构,让你对整个流程有一个了解,此部分转载自:详解AST抽象语法树
原文为:
浅谈 AST
先来看一下把一个简单的函数转换成AST之后的样子。
-
// 简单函数 -
function square(n) { -
return n * n; -
} -
// 转换后的AST -
{ -
type: "FunctionDeclaration", -
id: { -
type: "Identifier", -
name: "square" -
}, -
params: [ -
{ -
type: "Identifier", -
name: "n" -
} -
], -
... -
}
从纯文本转换成树形结构的数据,每个条目和树中的节点一一对应。
纯文本转AST的实现
当下的编译器都做了纯文本转AST的事情。
一款编译器的编译流程是很复杂的,但我们只需要关注词法分析和语法分析,这两步是从代码生成AST的关键所在。
第一步:词法分析,也叫扫描scanner
它读取我们的代码,然后把它们按照预定的规则合并成一个个的标识 tokens。同时,它会移除空白符、注释等。最后,整个代码将被分割进一个 tokens 列表(或者说一维数组)。
-
const a = 5; -
// 转换成 -
[{value: 'const', type: 'keyword'}, {value: 'a', type: 'identifier'}, ...]
当词法分析源代码的时候,它会一个一个字母地读取代码,所以很形象地称之为扫描 - scans。当它遇到空格、操作符,或者特殊符号的时候,它会认为一个话已经完成了。
第二步:语法分析,也称解析器
它会将词法分析出来的数组转换成树形的形式,同时,验证语法。语法如果有错的话,抛出语法错误。
-
[{value: 'const', type: 'keyword'}, {value: 'a', type: 'identifier'}, ...] -
// 语法分析后的树形形式 -
{ -
type: "VariableDeclarator", -
id: { -
type: "Identifier", -
name: "a" -
}, -
... -
}
当生成树的时候,解析器会删除一些没必要的标识 tokens(比如:不完整的括号),因此 AST 不是 100% 与源码匹配的。
解析器100%覆盖所有代码结构生成树叫做CST(具体语法树)。
用例:代码转换之babel
babel 是一个 JavaScript 编译器。宏观来说,它分3个阶段运行代码:解析(parsing) — 将代码字符串转换成 AST抽象语法树,转译(transforming) — 对抽象语法树进行变换操作,生成(generation) — 根据变换后的抽象语法树生成新的代码字符串。
我们给 babel 一段 js 代码,它修改代码然后生成新的代码返回。它是怎么修改代码的呢?没错,它创建了 AST,遍历树,修改 tokens,最后从 AST中生成新的代码。
前言
抽象语法树(AST),是一个非常基础而重要的知识点,但国内的文档却几乎一片空白。
本文将带大家从底层了解AST,并且通过发布一个小型前端工具,来带大家了解AST的强大功能
Javascript就像一台精妙运作的机器,我们可以用它来完成一切天马行空的构思。
我们对javascript生态了如指掌,却常忽视javascript本身。这台机器,究竟是哪些零部件在支持着它运行?
AST在日常业务中也许很难涉及到,但当你不止于想做一个工程师,而想做工程师的工程师,写出vue、react之类的大型框架,或类似webpack、vue-cli前端自动化的工具,或者有批量修改源码的工程需求,那你必须懂得AST。AST的能力十分强大,且能帮你真正吃透javascript的语言精髓。
事实上,在javascript世界中,你可以认为抽象语法树(AST)是最底层。 再往下,就是关于转换和编译的“黑魔法”领域了。
人生第一次拆解Javascript
小时候,当我们拿到一个螺丝刀和一台机器,人生中最令人怀念的梦幻时刻便开始了:
我们把机器,拆成一个一个小零件,一个个齿轮与螺钉,用巧妙的机械原理衔接在一起…
当我们把它重新照不同的方式组装起来,这时,机器重新又跑动了起来——世界在你眼中如获新生。
通过抽象语法树解析,我们可以像童年时拆解玩具一样,透视Javascript这台机器的运转,并且重新按着你的意愿来组装。
现在,我们拆解一个简单的add函数
-
function add(a, b) { -
return a + b -
}
首先,我们拿到的这个语法块,是一个FunctionDeclaration(函数定义)对象。
用力拆开,它成了三块:
-
一个id,就是它的名字,即add
-
两个params,就是它的参数,即[a, b]
-
一块body,也就是大括号内的一堆东西
add没办法继续拆下去了,它是一个最基础Identifier(标志)对象,用来作为函数的唯一标志,就像人的姓名一样。
-
{ -
name: 'add' -
type: 'identifier' -
... -
}
params继续拆下去,其实是两个Identifier组成的数组。之后也没办法拆下去了。
-
[ -
{ -
name: 'a' -
type: 'identifier' -
... -
}, -
{ -
name: 'b' -
type: 'identifier' -
... -
} -
]
接下来,我们继续拆开body
我们发现,body其实是一个BlockStatement(块状域)对象,用来表示是{return a + b}
打开Blockstatement,里面藏着一个ReturnStatement(Return域)对象,用来表示return a + b
继续打开ReturnStatement,里面是一个BinaryExpression(二项式)对象,用来表示a + b
继续打开BinaryExpression,它成了三部分,left,operator,right
-
operator 即+
-
left 里面装的,是Identifier对象 a
-
right 里面装的,是Identifer对象 b
就这样,我们把一个简单的add函数拆解完毕,用图表示就是
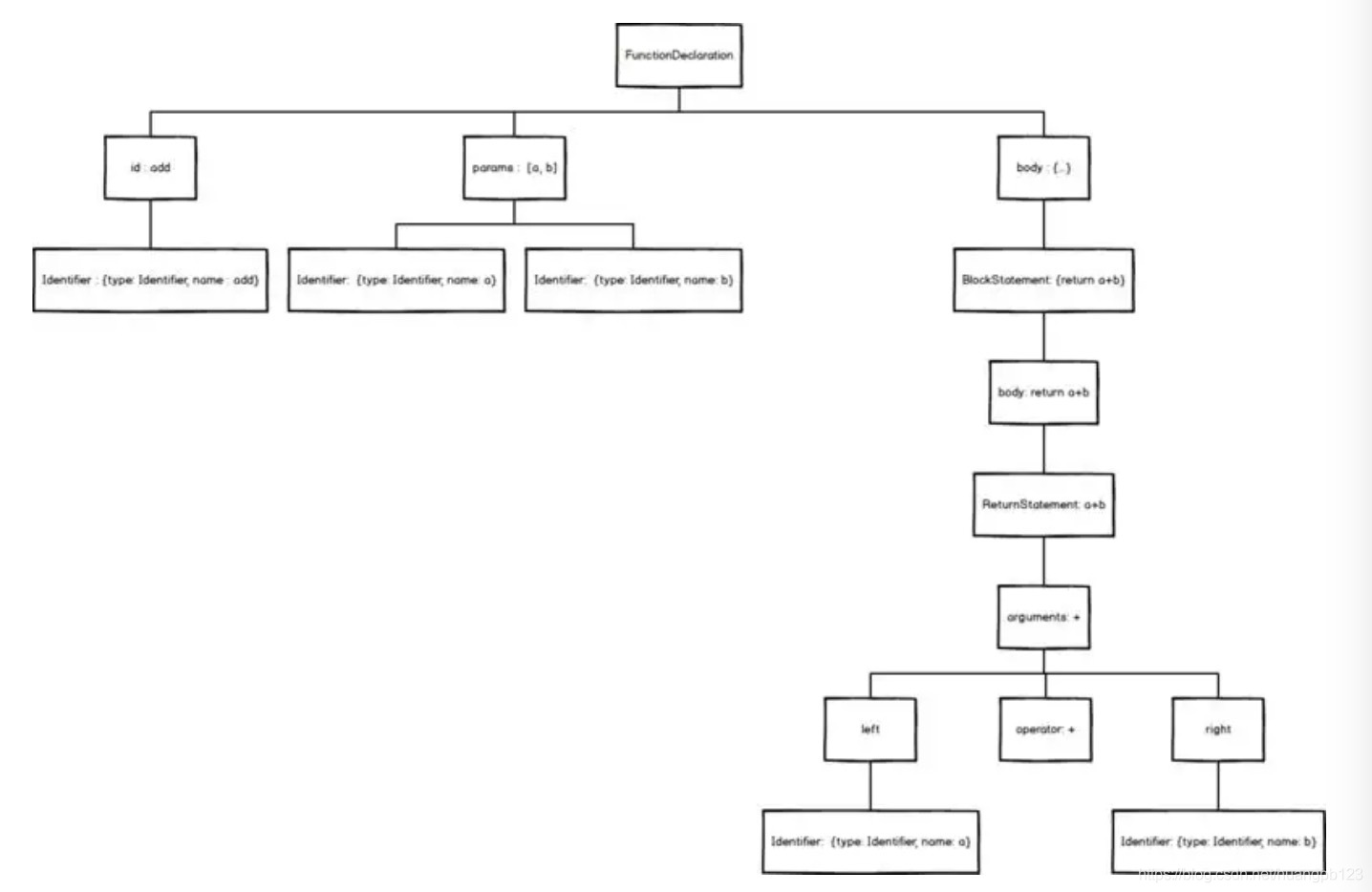
看!抽象语法树(Abstract Syntax Tree),的确是一种标准的树结构。
那么,上面我们提到的Identifier、Blockstatement、ReturnStatement、BinaryExpression, 这一个个小部件的说明书去哪查?
第三部分: Eclipse AST的获取与访问
此部分教你如何使用eclipse的AST,通过第三部分,你可以队AST的细节进一步的了解。对如何操纵AST有更清楚的理解。此部分转自作者刘伟:【Eclipse AST】AST的获取与访问,此部分提到了访问者模式,通过此模式对AST进行访问,想多了解访问者模式见链接:
原文为:
Eclipse中的Eclipse JDT提供了一组访问和操作Java源代码的API,Eclipse AST是其中一个重要组成部分,它提供了AST、ASTParser、ASTNode、ASTVisitor等类,通过这些类可以获取、创建、访问和修改抽象语法树。
首先需要掌握如何将Java源代码转换为AST,即解析源代码。Eclipse AST提供了ASTParser类用于解析源代码,ASTParser有两种导入源代码的方式,一种是以Java Model的形式,另一种是以字符数组的形式。ASTParser的创建与使用如下:
ASTParser astParser = ASTParser.newParser(/*API Level*/);
astParser.setSource(/*Source Code*/);
参数说明如下:
● API Level:Java编程规范(Java Language Specification,简写为JLS),此参数为常量,例如AST.JLS3。
● Source Code:方法setSource()针对不同形式的源代码作为参数而进行了重载,主要分类为字符数组形式(char[])和JavaModel形式(ICompilationUnit、IClassFile等)。
如果传入的字符数组不是完整的一个Java文件,而是一个表达式或语句,又怎么办呢?可以按照以下代码对ASTParser进行设置:
astParser.setKind(/*Kind of Construct*/);
其中Kind of Construct是所需解析的代码的类型,包括:
● K_COMPILATION_UNIT:编译单元,即一个Java文件
● K_CLASS_BODY_DECLARATIONS:类的声明
● K_EXPRESSION:单个表达式
● K_STATEMENTS:语句块
创建并设定好ASTParser后,便可以开始源代码与AST的转换,代码如下:
CompilationUnit result = (CompilationUnit) (astParser.createAST(null));
createAST()方法的参数类型为IProgressMonitor,用于对AST的转换进行监控,不需要的话就填个null即可。本代码示例是以待解析的源代码为一完整的Java文件(对应一个编译单元Compilation Unit)为前提的,所以在转换为AST后直接强制类型转换为CompilationUnit。CompilationUnit是ASTNode的子类,指的就是整个Java文件,也是AST的根节点。
下面是一个简单的工具类,用于将源代码以字符数组形式解析为AST,其中getCompilationUnit()方法的输入参数为需解析的Java源代码文件路径,返回值为该文件对应的CompilationUnit节点:
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.eclipse.jdt.core.dom.AST;
import org.eclipse.jdt.core.dom.ASTParser;
import org.eclipse.jdt.core.dom.CompilationUnit;
public class JdtAstUtil {
/**
* get compilation unit of source code
* @param javaFilePath
* @return CompilationUnit
*/
public static CompilationUnit getCompilationUnit(String javaFilePath){
byte[] input = null;
try {
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(javaFilePath));
input = new byte[bufferedInputStream.available()];
bufferedInputStream.read(input);
bufferedInputStream.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
ASTParser astParser = ASTParser.newParser(AST.JLS3);
astParser.setSource(new String(input).toCharArray());
astParser.setKind(ASTParser.K_COMPILATION_UNIT);
CompilationUnit result = (CompilationUnit) (astParser.createAST(null));
return result;
}
}
至此便将源代码转化为了AST,接下来要做的就是访问节点,需要学习两个Eclipse AST的核心类:
● ASTNode:AST节点类,在上一篇文章和上文中都有提到,由于节点种类太多,在此不一一赘述(后面专门写一篇独立的文章来介绍各种不同类型的ASTNode),但需要明确的是所有的节点类型都是ASTNode的子类,至于某一个节点源代码具体到底是什么节点,可以通过ASTView来查看。
● ASTVisitor:AST访问者类,它针对不同类型的节点提供了一系列重载的visit()和endvisit()方法,意思就是访问到该类型的节点时执行visit()方法,访问完该类型节点后执行endvisit()方法。其中,visit()方法需返回boolean类型的返回值,表示是否继续访问子节点。另外ASTVisitor还提供了preVisit()和postVisit()方法,参数类型为ASTNode,也就是说不论哪种类型的节点,访问前后都要分别执行preVisit()和postVisit()。这些方法的具体实现由ASTVisitor的子类负责,如果不需要对所访问到的节点做处理,则无需在ASTVisitor的子类中覆盖这些方法。
Eclipse AST访问节点这一部分的设计采用了访问者模式,不同类型的节点是待访问的具体元素,ASTNode充当抽象元素角色,ASTVisitor充当抽象访问者,而我们自己写的ASTVisitor的子类充当具体访问者,而程序代码就是对象结构,包含了不同种类的节点供访问者来访问。
在使用 Eclipse AST访问节点时需要先声明一个类继承自ASTVisitor,即增加具体访问者类,并覆盖相应的方法,编写需执行的操作,实例化这个访问者类后调用ASTNode的accept()方法,将ASTVisitor作为参数传入,就可以执行访问了,此处对应了访问者模式的“双重分派”机制,如果不熟悉的童鞋,可以先学习一下访问者模式,。【操作复杂对象结构——访问者模式】。
下面给出一个示例,实现输出给定Java文件中所声明的类名、方法名和属性名,基本步骤如下:
(1) 通过ASTView确定类、方法和属性的声明对应的AST节点分别是TypeDeclaration、MethodDeclaration和FieldDeclaration,FieldDeclaration类比较特殊,因为一个FieldDeclaration下可能有多个同类型的属性被声明,形如“privateint a, b;”。
(2) 创建一个新的访问者子类,继承自ASTVisitor,并覆盖参数类型为TypeDeclaration、MethodDeclaration和FieldDeclaration的visit()方法,由于需要遍历所有节点,因此将返回值都设为true。
(3) TypeDeclaration、MethodDeclaration可以直接获得相关的名字并输出,而FieldDeclaration需要遍历它的子节点VariableDeclarationFragment,由于FieldDeclaration提供了返回所有VariableDeclarationFragment的方法,因此这里直接采用for循环遍历即可。
详细代码如下:
import org.eclipse.jdt.core.dom.ASTVisitor;
import org.eclipse.jdt.core.dom.FieldDeclaration;
import org.eclipse.jdt.core.dom.MethodDeclaration;
import org.eclipse.jdt.core.dom.TypeDeclaration;
public class DemoVisitor extends ASTVisitor {
@Override
public boolean visit(FieldDeclaration node) {
for (Object obj: node.fragments()) {
VariableDeclarationFragment v = (VariableDeclarationFragment)obj;
System.out.println("Field:\t" + v.getName());
}
return true;
}
@Override
public boolean visit(MethodDeclaration node) {
System.out.println("Method:\t" + node.getName());
return true;
}
@Override
public boolean visit(TypeDeclaration node) {
System.out.println("Class:\t" + node.getName());
return true;
}
}
下面提供一个测试类,对上述解析源代码的工具类(JdtAstUtil)和访问AST的访问者类(DemoVisitor )进行测试:
import org.eclipse.jdt.core.dom.CompilationUnit;
import com.ast.util.JdtAstUtil;
import com.ast.visitor.DemoVisitor;
public class DemoVisitorTest {
public DemoVisitorTest(String path) {
CompilationUnit comp = JdtAstUtil.getCompilationUnit(path);
DemoVisitor visitor = new DemoVisitor();
comp.accept(visitor);
}
}
提供一个待处理的简单Java源代码文件(ClassDemo.java)如下:
public class ClassDemo {
private String text = "Hello World!", text2;
public void print(int value) {
System.out.println(value);
}
public void input(String value) {
text2 = value;
}
}
显示结果为:
图1 测试运行结果
上述示例代码DemoVisitor还有点小瑕疵,例如TypeDeclaration节点其实不仅表示了类的声明,还包括了接口的声明,实际运用中需要根据情况使用TypeDeclaration提供的isInterface()方法来进行过滤。这也说明了一方面各位开发者需要认真了解各种不同类型的节点具有哪些特性、不同的节点类有哪些方法,另一方面开发者还需要对Java语言本身有较为深入的了解。
OK,本节有关AST的获取和访问就介绍到这里,,大家如果有兴趣的话可以做做如下两个练习:
(1) 寻找一个类的构造方法、抽象方法和Main方法;
(2) 统计一个If语句的Then语句块中语句的数量。
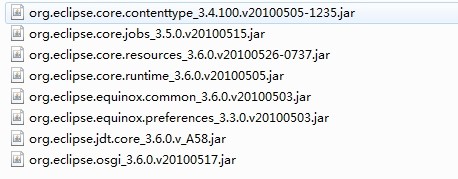
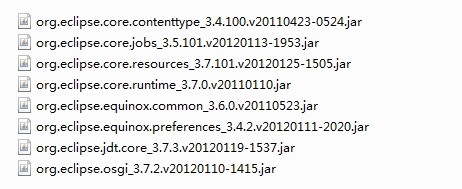
P.S.,本实例工程中需要导入的jar包如下:
org.eclipse.core.contenttype.jar
org.eclipse.core.jobs.jar
org.eclipse.core.resources.jar
org.eclipse.core.runtime.jar
org.eclipse.equinox.common.jar
org.eclipse.equinox.preferences.jar
org.eclipse.jdt.core.jar
org.eclipse.osgi.jar
例如这是我们之前用过的两组使用AST解析Java源文件的jar包(只有版本号不一样):
 支付宝打赏
支付宝打赏 微信打赏
微信打赏